GSA-Gaze: Generative Self-adversarial Learning for Domain Generalized Driver Gaze Estimation
Feb 13, 2024· ,,,,,
,,,,,
HAN Hongcheng
Zhiqiang Tian
Yuying Liu
Shengpeng Li
Dong Zhang
Shaoyi Du*
Corresponding author
·
0 min read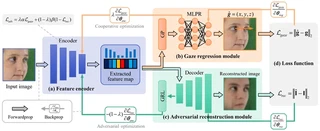
Abstract
Estimating driver gaze accurately is critical for the human-machine cooperative driving, but the significant facial appearance diversions caused by background, illumination, personal characteristics, etc. pose a challenge to the generalizability of gaze estimation models. In this paper, we propose the generative self-adversarial learning mechanism for generalized gaze estimation that aims to learn general gaze features while eliminating sample-specific features and preventing cross-domain feature over-fitting. Firstly, to reduce information redundancy, the feature encoder is designed based on pyramid-grouped convolution to extract a sparse feature representation from the facial appearance. Secondly, the gaze regression module supervises the model to learn as many gaze-relevant features as possible. Thirdly, the adversarial image reconstruction task prompts the model to eliminate the domain-specific features. The adversarial learning of the gaze regression and the image reconstruction tasks guides the model to learn only general gaze features across domains, preventing cross-domain feature over-fitting, enhancing the domain generalization capability. The results of cross-domain testing of four active gaze datasets prove the effectiveness of the proposed method.
Type
Publication
IEEE International Conference on Intelligent Transportation Systems (ITSC)
License
CC-BY-4.0

Authors
HAN Hongcheng
(he/him)
PhD Candidate in Control Science and Engineering
Han Hongcheng (韩泓丞) received the degree of B.Eng. in School of Energy and Power Engineering, Xi’an Jiaotong University, Xi’an, China in 2020.
Since then, he is studying for Ph.D. degree in Institute of Artificial Intelligence and Robotics, Xi’an Jiaotong University.
His interests focus on intelligent transportation and medical image analysis, specializing in Multimodal data fusion and Image Synthesis.